A Private AI Assistant
Large Language Models (LLMs) use Neural Networks to identify and learn patterns from large amounts of text documents. Simply put, they read so much text, that whenever you give them the beginning of a sentence, they have a very high chance to predict how it continues.
This ability of predicting the next word for a given sentence has opened the door to interacting with machines using natural language, a whole new interface.
But at the same time, the fact that they sound so natural and knowledgeable is precisely their biggest flaw. They can only generate text that sound natural and makes sense, but they have no clue of what they are talking about. They frequently hallucinate and provide false information that looks like factual.
In addition, LLMs can only be trained on public data, and therefore can only answer questions with general knowledge. If you need one of such models to talk about your company processes, or the content in your laptop’s hard drive, you need some additional process to give it access to that data.
In this article I will cover how to build an LLM-based private AI assistant that knows what it’s talking about. And the whole system will run in your local computer, so that your data will stay safe and private.
The technique we will use is called Retrieval-Augmented Generation and consists on giving an LLM some context based on information that was not part of the initial training data set. We will create a system that stores a set of documents, and will look for relevant documents whenever a query from the user is received to provide them as context to the LLM.
To build this system, we will use:
- Micronaut as the application framework.
- LangChain4J for the AI tooling.
- JLama as the inference engine, to run the LLM locally.
- Viswa Prakash’ farming dataset as sample data. We will build a system that knows how to answer questions about farming without hallucinations.
Disclaimer
The goal here is to learn. We will not use the easiest way to build a RAG system with LangChain4J, nor the most powerful. But the system we will build is a good hands-on example for you to learn about the moving parts of such systems. If you need to build a system like this for producdtion, take a look at the official LangChain4J documentation for a description of the several flavours you can choose from.
As always, you can find the source code for this project in this Github repository.
Retrieval-Augmented Generation explained
Retrieval-Autmented Generation (RAG) consists on giving an LLM access to a private data store, so that it takes that data into account when answering your questions. When a RAG system receives a question from the user, it follows this routine:
- Search the private data store for documents relevant for the query.
- Compose a prompt that contains the retrieved data, and
- Send the prompt to the LLM, and forward the answer to the user.
How the relevant documents are found
To find the documents relevant to the user query, we typically do a semantic search. Semantic searches are a powerful tool because they can identify text fragments that are similar to the user query in their meaning. Even if they have no words in common.
The magic trick here (one of my favorite ideas in the AI world) is to convert the text to vectors. If we can find a way to convert a text into a vector keeping information about its meaning, then we have all the tools in geometry world to work with it.
In particular, we can find how close two vectors are using different metrics:
- The cosine of angle they form
- The euclidean distance between their tips
- The number of steps needed to walk in a grid, from one tip to the other
- And many others.
So, if we can convert texts to vectors, keeping their meaning, then we can use geometry to calculate similarities. And we can, with another technique known as “embedding”.
What Are Embeddings?
In machine learning, embedding refers to a knowledge representation technique where complex data is represented as vectors in a reduced-dimensionality vector space. This is done by using a specific type of models trained for this task.
Choosing the best model for your particular data set is one of the main things you can do to achieve good results. I recommend you to try different embedding models to find the one that works best for your data.
In this example I am creating embeddings for a query and a set of candidate questions, and comparing how the candidates are sorted for two different embedding models. As you can see, the results are quite different:
Query: Is it ok to water my tomatoes every day?
-> Candidates sorted with 'intfloat/e5-small-v2':
How often should I water tomato plants? (0.636699)
How can I control pests on my cotton farm? (0.617073)
Which crop is best for sandy soil? (0.615944)
What fertilizer is good for wheat crops? (0.603053)
What is the best time to plant rice? (0.578878)
======================================
-> Candidates sorted with 'answerdotai/answerai-colbert-small-v1':
What fertilizer is good for wheat crops? (0.845185)
How can I control pests on my cotton farm? (0.819669)
What is the best time to plant rice? (0.785921)
Which crop is best for sandy soil? (0.732096)
How often should I water tomato plants? (0.719052)
======================================
How the RAG system works
So let’s take a look at the RAG system to understand how it works. In the following diagram you can see the main moving parts, and the order in which they participate when a user sends a message:
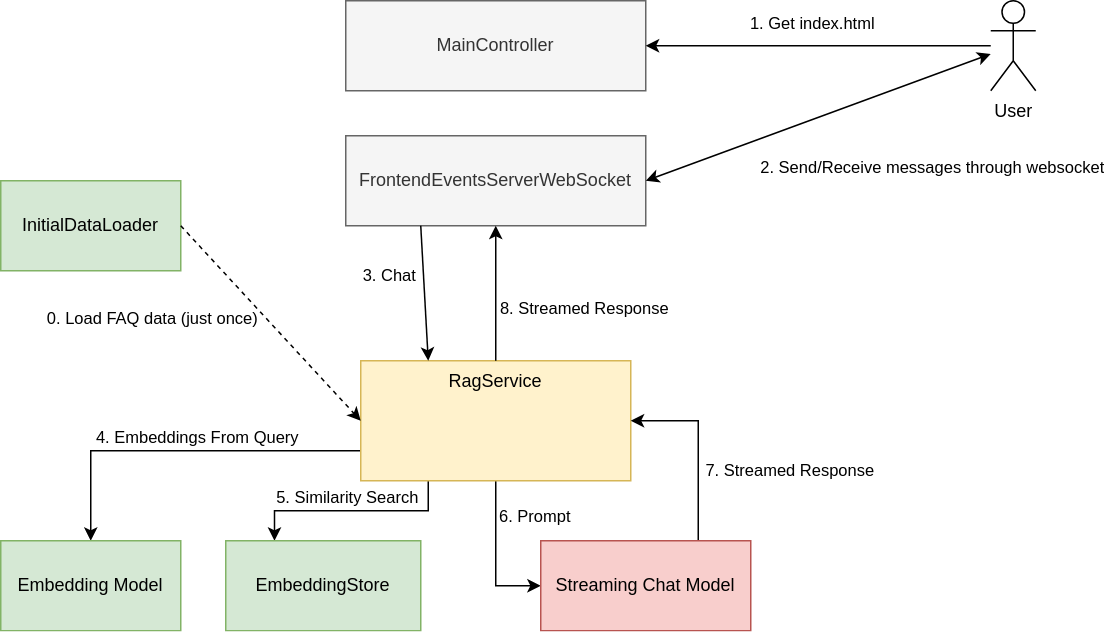
The center of this project is the concept of RagService, a class implementing the following interface:
public interface RagService {
void ingest(Document document);
default void ingest(DocumentCollection documentCollection) {
documentCollection.stream().forEach(this::ingest);
}
void chat(RagQuery query, Consumer<RagTokens> ragTokensConsumer);
void serialize();
}
A RagService has three main functionalities:
- It can load documents to be used as context when a user query is received.
- It can chat with the user, answering their questions with sequences of tokens (a token can be a word, a part of a word, or a punctuation sign).
- It can also serialize its internal state to avoid having to re-load all the documents on every execution.
Let us study each step of the user query processing logic.
0. Initial data load
The fist thing we need to do when the system starts is to load the data. I have used an Application Event Listener that runs when the context startup is complete:
@Singleton
@Requires(property = "remo.load-data", value = "true")
public class InitialDataLoader implements ApplicationEventListener<StartupEvent> {
...
private final ResourceResolver resourceResolver;
private final String dataFilePath;
private final RagService ragService;
...
@Async(TaskExecutors.BLOCKING)
@Override
public void onApplicationEvent(StartupEvent event) {
loadData();
ragService.serialize();
}
...
}
Some interesting details:
- The
@Requiresannotation allows to disable this data loading feature. - The
@Asyncannotation instructs Micronaut to execute this method in a background thread, instead of the main event loop. - After loading the data, this method calls
serialize()on the RagService, to persist its current state avoiding the need to reload the same data every time.
Here is the loadData() method:
private void loadData() {
logger.info("Loading data from {}", dataFilePath);
var url =
resourceResolver
.getResource(dataFilePath)
.orElseThrow(
() ->
new DocumentLoadException(
"Could not load data from %s".formatted(dataFilePath)));
var documentCollection = new CSVFaqDocumentCollection(url.getPath(), 0, 1);
ragService.ingest(documentCollection);
}
The method will first load the CSV data file from classpath, and then passes it to the RagService’s ingest method wrapped in a CSVFaqDocumentCollection.
You can see the full source of this bean here.
The LangChain4J version of RagService implements the ingest method by using a LangChain4J’s RAG tooling to
- split the document into smaller text fragments
- create the embeddings from those fragments, and
- add all the embeddings to an in-memory embedding store
...
private final DocumentSplitter splitter = DocumentSplitters.recursive(200, 0);
private final InMemoryEmbeddingStore<TextSegment> embeddingStore;
private EmbeddingModel embeddingModel;
...
@Override
public void ingest(Document document) {
log.info("Ingesting document: {}", document.getId());
var content = document.getTextContent();
var metadata = new Metadata(document.getMetadata());
var l4Document = dev.langchain4j.data.document.Document.from(content, metadata);
var segments = splitter.split(l4Document);
var embeddingModel = getEmbeddingModel();
var embeddings = embeddingModel.embedAll(segments).content();
embeddingStore.addAll(embeddings, segments);
}
When all the documents are loaded the system is ready to answer the user messages.
1. Load HTML document
The user interacts with this system by visiting https://localhost:8080 with a web browser. The frontend is a vanilla Javascript project automated with vite.
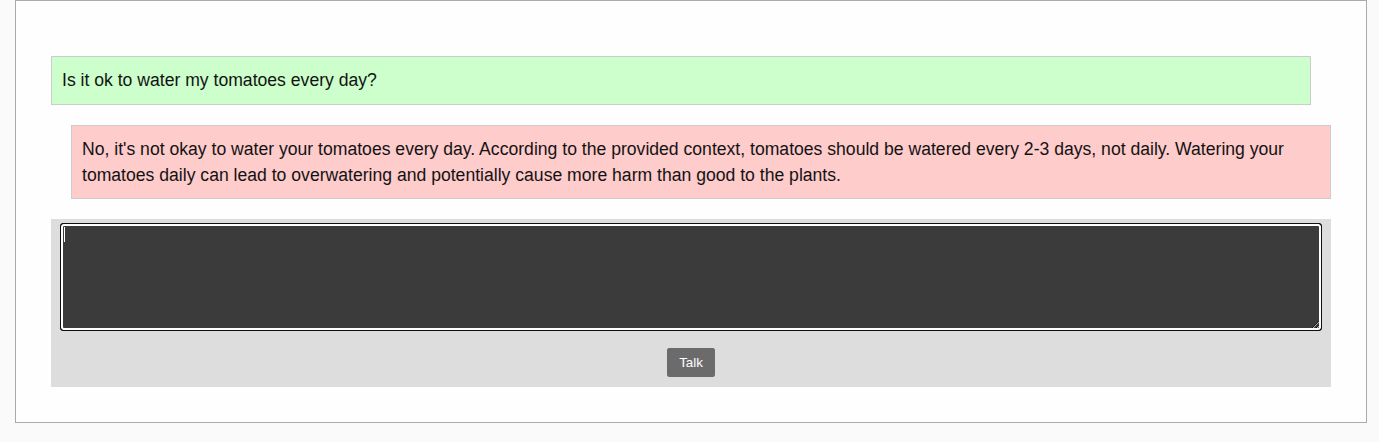
The frontend contains only two components that communicate through custom events:
-
chat.js handles the UI, listening for the
clickevent in the main PTT button, and forresponse-tokens-receivedas dispatched when the response from the server comes back. -
websocket.js handles the communication with the backend. It listens for the
user-talkedevent that the UI dispatches when the user clicks the button, sends a message through the open websocket, and triggers custom events whenever a message is received from server.
Besides the websocket communication, which I’ll cover next, there is nothing fancy about the frontend.
2. Websocket Conversation
The conversation starts when the user clicks on the Talk button. As we have seen, the chat component notifies the websocket and it sends a new message through the socket.
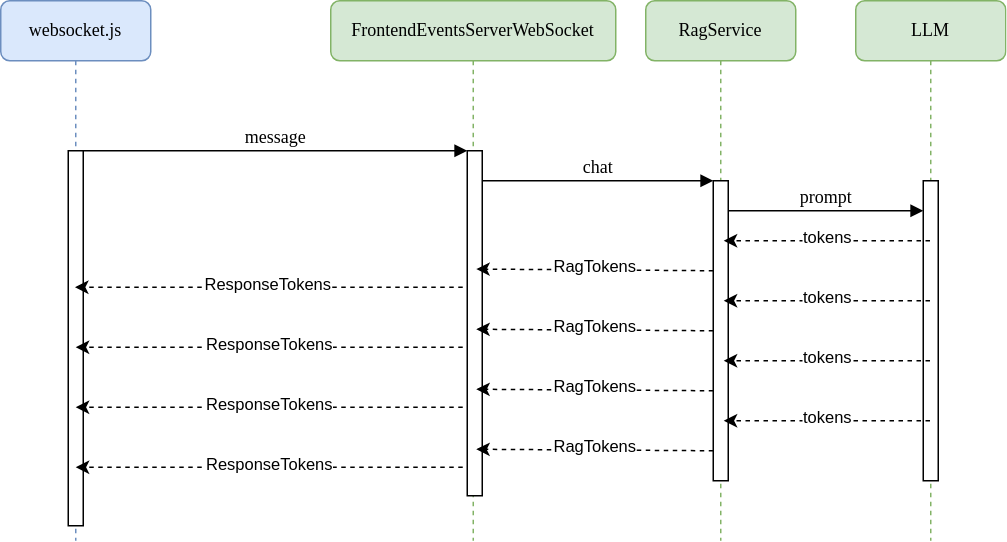
When the server receives that messages, it invokes the void chat(RagQuery, Consumer<RagTokens>) method on RagServer, passing two arguments:
- A RagQuery instance that represents the user query.
- A standard Consumer function that will be invoked as fragments of the response for this query are received.
private void queryRagService(WebSocketSession session, UserMessage userMessage) {
ragService.chat(
RagQuery.of(userMessage.queryId(), userMessage.message()),
tokens -> {
session.sendAsync(ResponseTokens.of(tokens));
});
}
As the response fragments are received from the LLM, they will be dispatched as messages back to the UI through the websocket.
3. Handle User Messages
LangChain4JRagService is the default implementation of the RagService interface. This is how the chat method is implemented:
@Override
public void chat(RagQuery query, Consumer<RagTokens> ragTokensConsumer) {
Prompt prompt = buildPrompt(query);
var userMessage = prompt.text();
log.info("Generated prompt\n{}", userMessage);
getChatModel()
.chat(
userMessage,
new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String s) {
ragTokensConsumer.accept(RagTokens.partialResponse(query.uuid(), s));
}
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
log.info("Response complete: {}", chatResponse.aiMessage().text());
}
@Override
public void onError(Throwable throwable) {
log.error(throwable.getMessage(), throwable);
}
});
}
First, the prompt is built. This implies creating the embeddings from the query and searching for similar documents in the store, and will be covered in the following sections.
Once the prompt is built, it is sent to the StreamingChatModel, that will provide the model response token-by-token, instead of waiting to the entire text to be generated.
An instance of StreamingChatResponseHandler is provided as second argument to handle the response from the LLM.
The getChatModel method is responsible for creating the model the first time it is requested, and keeping the reference for future uses:
private StreamingChatModel getChatModel() {
if (chatModel == null) {
chatModel =
JlamaStreamingChatModel.builder().modelName(CHAT_MODEL).temperature(TEMPERATURE).build();
}
return chatModel;
}
You can choose any of the available models for JLama, my recomendation is to try with different alternatives as the results can be substantially different. The first time you run this code in your computer, the JLama library will download the selected model to a local cache folder.
4. Create Embeddings From The Query
It is critical for the semantic search to find relevant documents that we use the same model to create the embeddings for the query that we used with the documents. I have created a getEmbeddingModel method, equivalent to getChatModel:
private EmbeddingModel getEmbeddingModel() {
if (embeddingModel == null) {
embeddingModel = JlamaEmbeddingModel.builder().modelName(EMBEDDING_MODEL).build();
}
return embeddingModel;
}
The first time your run this, it will download the selected embedding model, so that it can be reused in later executions. Once the model is available, we will simply use the embed(String) method to vectorize our query:
Embedding questionEmbedding = getEmbeddingModel().embed(query.text()).content();
5. Vector Similarity Search
Finding relevant documents in the storage involves doing a semantic search. The search method in the InMemoryEmbeddingStore is quite straight forward:
@Override
public EmbeddingSearchResult<Embedded> search(EmbeddingSearchRequest embeddingSearchRequest) {
Comparator<EmbeddingMatch<Embedded>> comparator = comparingDouble(EmbeddingMatch::score);
PriorityQueue<EmbeddingMatch<Embedded>> matches = new PriorityQueue<>(comparator);
Filter filter = embeddingSearchRequest.filter();
for (Entry<Embedded> entry : entries) {
if (filter != null && entry.embedded instanceof TextSegment) {
Metadata metadata = ((TextSegment) entry.embedded).metadata();
if (!filter.test(metadata)) {
continue;
}
}
double cosineSimilarity = CosineSimilarity.between(entry.embedding, embeddingSearchRequest.queryEmbedding());
double score = RelevanceScore.fromCosineSimilarity(cosineSimilarity);
if (score >= embeddingSearchRequest.minScore()) {
matches.add(new EmbeddingMatch<>(score, entry.id, entry.embedding, entry.embedded));
if (matches.size() > embeddingSearchRequest.maxResults()) {
matches.poll();
}
}
}
List<EmbeddingMatch<Embedded>> result = new ArrayList<>(matches);
result.sort(comparator);
Collections.reverse(result);
return new EmbeddingSearchResult<>(result);
}
Since the embeddings are all in an in-memory collection, all it needs to do is iterate that collection and calculate the vector similarity (in this case it is using cosine similarity) between each one of them and the provided query. Those that have a similarity above the threshold will be kept for the result.
To invoke the search method, we only need to build an EmbeddingSearchRequest:
private List<EmbeddingMatch<TextSegment>> getRelevantEmbeddings(RagQuery query) {
Embedding questionEmbedding = getEmbeddingModel().embed(query.text()).content();
EmbeddingSearchRequest embeddingSearchRequest =
EmbeddingSearchRequest.builder()
.queryEmbedding(questionEmbedding)
.maxResults(2)
.minScore(0.85)
.build();
return embeddingStore.search(embeddingSearchRequest).matches();
}
6. Build Prompt
Once we have the relevant content from our data store, we can build the prompt. There are multiple ways to build a prompt in a RAG system, in this example I will use a static template:
private final PromptTemplate promptTemplate =
PromptTemplate.from(
"Context information is below.:\n"
+ "------------------\n"
+ "{{information}}\n"
+ "------------------\n"
+ "Given the context information and not prior knowledge, answer the query.\n"
+ "Query: {{question}}\n"
+ "Answer:");
The buildPrompt method will be responsible for retrieving the relevant embeddings, and replacing the placeholders in the prompt template.
private Prompt buildPrompt(RagQuery query) {
List<EmbeddingMatch<TextSegment>> relevantEmbeddings = getRelevantEmbeddings(query);
String information =
relevantEmbeddings.stream()
.map(embeddingMatchMapper::map)
.distinct()
.collect(joining("\n\n"));
Map<String, Object> promptInputs = new HashMap<>();
promptInputs.put("question", query.text());
promptInputs.put("information", information);
return promptTemplate.apply(promptInputs);
}
This how a typical prompt sent to the LLM will look like:
Context information is below.:
------------------
Tomato plants should be watered every 2-3 days, keeping the soil moist but not waterlogged.
------------------
Given the context information and not prior knowledge, answer the query.
Query: Is it ok to water my tomatoes every day?
Answer:
7. Handle Response Stream
As we saw, LLMs are linear text generators, they work in a loop where the initial text is used to generate the next token, and the resulting string is re-introduced to generate one more, until there are no more tokens with a probability above a given threshold.
This routine justifies using a streaming approach in applications needing to interact with an LLM. Instead of waiting for the model to generate the complete text, we can parse the response token by token, providing a much better user experience.
This is why I am using a StreamingChatModel and replicating the same approach by making the chat method in RagService receive a function as a second parameter.
8. Forward Response Stream To Websocket
As we saw, the Consumer we provide to RagService:chat is sending every token it receives as a new message over the websocket:
private void queryRagService(WebSocketSession session, UserMessage userMessage) {
ragService.chat(
RagQuery.of(userMessage.queryId(), userMessage.message()),
tokens -> {
session.sendAsync(ResponseTokens.of(tokens));
});
}
The message is received in the Javascript side with a new UI event that updates the user interface:
function handleChatResponseReceived(event){
console.info(event);
const conversationContainer = document.getElementById('remo-conversation');
const message = event.detail.message;
const queryId = message.queryId;
const isComplete = message.isComplete;
const tokens = message.tokens;
let messageContainer = document.getElementById('response-'+queryId);
if(!messageContainer){
messageContainer = document.createElement("div");
messageContainer.classList.add("chat", "bot");
messageContainer.id = 'response-'+queryId;
conversationContainer.appendChild(messageContainer);
}
if(tokens){
messageContainer.innerHTML += tokens;
}
if(isComplete){
messageContainer.classList.add("complete");
}
}
Note that the uuid in the query is used to identify the correct conversation thread, so the text is appended to the right container.
Conclusions
In this article we have built a complete RAG system that is able to use locally stored documents to generate grounded answers to user questions.
There are many ways in which we can alter this example to enhance the quality of the responses, I will leave that to you as exercise. Take a look at the different parameters you can pass when creating the models, for example.
Another thing you can try is to use different embedding models. As we have seen, that decision has a big impact on the semantic search results.
In any case, the main feature of this system is that it runs 100% locally, it does not use any external API to generate the embeddings or to run the LLM. This can make the difference when dealing with sensitive data, or private corporate content.
RAG systems are a great option for private AI assistants. I hope you found this project useful.